Learn to Pay Attention
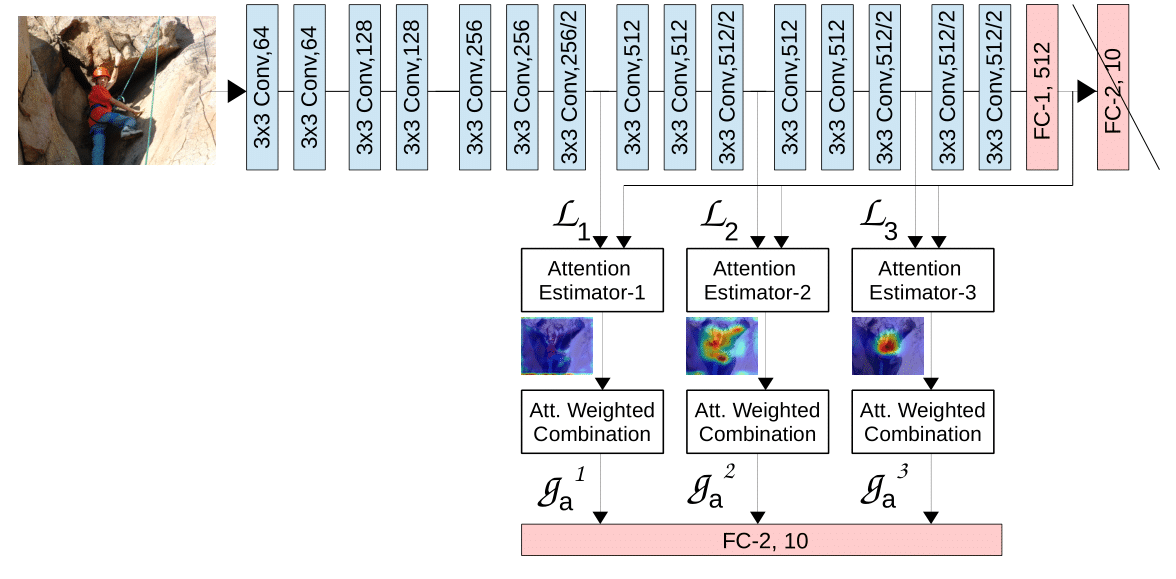
We propose an end-to-end-trainable attention module for convolutional neural network (CNN) architectures for image classification. The module takes as input the 2D feature vector maps which form the intermediate representations of the input image at different stages in the CNN pipeline, and outputs a 2D matrix of scores for each map. Standard CNN architectures are trained under the constraint that a convex combination of the intermediate 2D feature vectors, as parameterised by the score matrices, must alone be used for classification. Our experimental observations provide clear evidence to the effect that the learned scores simulate 'attention'by amplifying the relevant and suppressing the irrelevant or misleading regions of the input image. Thus, the proposed function is able to bootstrap standard CNN architectures for the task of image classification and demonstrate superior generalisation.
[paper]
[code]
[video]